让不懂建站的用户快速建站,让会建站的提高建站效率!

发布日期:2025-03-18 08:41 点击次数:63
本文将带你久了探索大言语模子的里面寰宇,从输入到输出的每一个重要,揭示其若何将东说念主类言语转机为智能回复。
大语大言语模子的中枢架构是一个超等大脑,主要由三部分组件,别离是输入、中间层和输出层。输入层的主要作用是把东说念主类的言语转机成机器能剖析的数字秀美。中间层的中枢是 Transformer,主要的作用是对输入的数字序列进行深度语义分析,培植词与词之间的关联。终末是输出层,输出层的主要作用是把中间层惩办后的数字秀美规复成东说念主类能剖析的内容(翰墨、语音等)。举个肤浅的例子来剖析一下,比如我到福周菜馆点餐,我输出:“我要鱼丸和 [MASK]” ->大模子找到与 “鱼丸” 向量最接近的词(如 “拌面”,因为福州东说念主常搭配吃)->“我要鱼丸和拌面”。
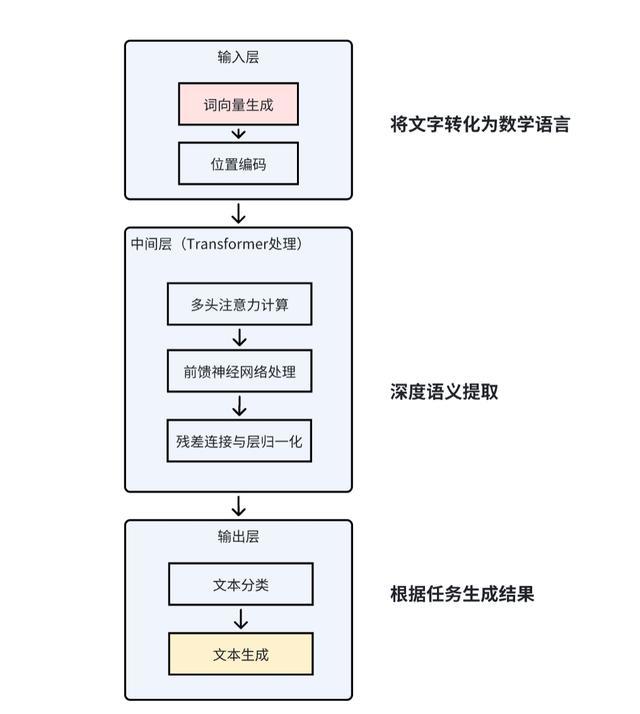
一、输入层
要让机器能剖析东说念主类言语,率先要将东说念主类言语(翰墨、语音等)转机为筹划机能惩办的数学秀美。输入层相等于是翻译官,把中英文翻译成机器言语。这层主要包括两个主要法子:
1、词向量生成
在诠释词向量生成之前,步伐略分词(Tokenization)的认识。分词是将句子拆分红最小语义单位(词或子词)。比如把咱们福州的鱼丸拆分红[“福州”, “鱼丸”]。这里波及到的本事有BPE(字节对编码)、WordPiece 等。
生成完分词后,需要将每个词鼎新为多维数字向量(雷同坐标),多维数字向量是由多个数字构成的 “坐标点”,这个坐标点能响应词的语义和语法信息。比如:“猫” → [0.2, -0.5, 0.7],不同词的向量空间位置响应语义关联。诚然,这些词的多维向量是通过预考试模子(如 Word2Vec)生成的。
为什么是多维向量?
如若是单维向量,则用 1 个数字(如 1 维)只可示意肤浅互异(比如用 0 示意 “猫”,1 示意 “狗”),但无法体现语义关联(如 “猫” 和 “狗” 齐属于动物)。词的多维数字向量是大模子的 “言语密码”,他的本体是将词映射到高维空间的坐标点,通过坐标距离和运算,让机器剖析词的语义、语法和逻辑关系。让模子能像东说念主类相似 “剖析” 言语背后的含义。
2、位置编码
给每个词添加位置信息(如 “福州” 是第 1 个词,“鱼丸” 是第 2 个词)。由于Transformer 并行惩办不依赖轨则,是以需出奇加入位置信息(如 “鱼丸” 在前和在后的好奇瞻仰好奇瞻仰不同)。比如:第 1 个词(福州) → [0.1, 0.9],第 2 个词(鱼丸) → [0.3, 0.8]
示例诠释
输入文本
“福州鱼丸和沙县小吃齐是福建的特点好意思食”
1. 词向量生成
通过预考试模子(如 Word2Vec)生成每个词的多维向量(假定示例):
福州 → [0.2, -0.5, 0.7]
鱼丸 → [0.3, -0.6, 0.8]
沙县小吃 → [0.4, 0.1, -0.3]
福建 → [0.1, 0.9, -0.2]
特点好意思食 → [0.7,股票高杠杆配资 0.3, 0.4]
2. 位置编码
给每个词添加位置信息(假定用正弦函数生成):
第 1 个词(福州) → [0.1, 0.9]
第 2 个词(鱼丸) → [0.3, 0.8]
第 3 个词(沙县小吃) → [0.5, 0.7]
第 4 个词(福建) → [0.7, 0.6]
第 5 个词(特点好意思食) → [0.9, 0.5]
最终输入向量:
每个词向量与位置编码拼接,举例: 福州 → [0.2, -0.5, 0.7, 0.1, 0.9]
二、中间层
1、Transformer 架构
Transformer的中枢任务是将原始词向量转机为富含语义关联的深度特征。它替代了传统轮回神经汇集(RNN),让大模子能并行惩办统共词。传统 RNN 需按轨则惩办词(如 “我→爱→中国”),Transformer 能同期惩办统共词,并通过防卫力机制捕捉远距离词的关联(如 “北京” 和 “齐门” 相隔很远仍能关联)。
2、防卫力机制(Attention)
自防卫力(Self-Attention)
自防卫力是为了让每个词 “包涵” 其他词的进击性。比如:翻译 “猫追老鼠” 时,“追” 需要包涵 “猫”(施动者)和 “老鼠”(受动者)。自防卫力筹划时,会先进行联系性打分:筹划 “追” 与 “猫”“老鼠” 的关联度(如 “追” 和 “猫” 的分数更高);然后再加权乞降:字据分数生成 “追” 的新向量(要点融入 “猫” 的信息)。
多头防卫力(Multi-Head Attention)
多头防卫力是为了从不同角度分析词关系(雷同用不同滤镜看归拢张相片)。比如:惩办 “苹果公司发布了新 iPhone”。多头防卫力为了捕捉更全面的语义关联,单干如下:
头 1:包涵公司与家具(“苹果”→“iPhone”)。
头 2:包涵算作与对象(“发布”→“iPhone”)。
头 3:包涵时辰或方位(若句子有 “今天”)。
防卫力筹划经过
词向量鼎新:每个词转为坐标点(如 “鱼丸”→[0.2, -0.5, 0.7])。
筹划联系性:“鱼丸” 对 “拌面” 的包涵度:字据向量距离打分(福州东说念主常搭配吃,配资平台分数高)。
生成新向量:“鱼丸” 的向量会要点交融 “拌面” 的信息(因为包涵度高)。
多头防卫力 = 多个自防卫力头 + 效果拼接。每个头寂然筹划自防卫力,然后将效果合并(雷同拼图)。示举例下
示例(以句子 “猫追老鼠” 为例):
-自防卫力头 1:包涵算作关系 → [猫:追,老鼠:被追]
-自防卫力头 2:包涵实体关系 → [猫:动物,老鼠:动物]
-多头效果:详细两个头的信息,得回更全面的剖析。
3、前馈神经汇集(Feed-Forward Network)
FFN是对防卫力惩办后的向量进行非线性变换(雷同炒菜时的调味),因为防卫力机制本体是线性加权,无法惩办复杂非线性关系,通过激活函数(如 ReLU)让模子学习更复杂的语义风物。比如:将 “鱼丸” 与 “福建” 的关联从 “地域特产” 进步为 “文化秀美”。
4、残差贯串与层归一化
残差贯串:将原始输入与 FFN 输出相加,防患信息丢失。
层归一化:圭表化数值范畴,确保结识性。
示例诠释
1. 多头防卫力(Multi-Head Attention)
通过 8 个头(假定)从不同角度分析词关系:
头 1(地域关系):
要点包涵 “福州” 和 “福建” 的关联,将它们的向量加权交融。
输出:[0.25, -0.4, 0.65, 0.12, 0.88](增强地域特征)。
头 2(食品类别):
包涵 “鱼丸” 和 “沙县小吃” 的相似性,交融后隆起 “小吃” 属性。
输出:[0.35, -0.5, 0.75, 0.32, 0.78]。
头 3(学问推理):
捕捉 “福建” 和 “特点好意思食” 的逻辑关系,说明 “福建有好意思食”。
输出:[0.65, 0.2, -0.15, 0.68, 0.52]。
拼接多头效果:
将 8 个头的输出拼接后通过线性层,得回每个词的新向量。
2. 前馈神经汇集(FFN)
对防卫力后的向量进行非线性变换: 福州 → [0.3, -0.6, 0.7, 0.1, 0.9](增强 “省会” 语义)。 福建 → [0.8, 0.7, -0.1, 0.7, 0.6](强化 “省份” 特征)。
3. 残差贯串与层归一化
残差贯串:将原始输入与 FFN 输出相加,防患信息丢失。 福州 → [0.2+0.3, -0.5+(-0.6), …] → [0.5, -1.1, …]。
层归一化:圭表化数值范畴,确保结识性。 福州 → [0.5/√(0.5²+…), …] → [0.2, -0.4, …]。
三、输出层
1、文分内类
文分内类的主要作用是把句子贴标签,并判断这个标签的概率。惩办经过包括“中间层追思的句子密码 → 分类筛子 → 概率筹划器 → 贴标签“。
中间层追思的句子密码:通过中间层依然把句子形成一串数字(比如 [0.8, 0.6, -0.3]),就像给句子生成一个 “数字身份证”。
分类筛子:用一个数学公式(雷同筛子)把这串数字形成两个分数。比如 [1.2, -0.5],代表 “是好意思食” 的可能性更高。
概率筹划器:把分数转机为百分比。比如 [77%, 23%],诠释 77% 概率是好意思食描摹,23% 概率不是。
比如:
输入:“这说念菜很可口”
输出:77% → 贴标签 “是好意思食”
2、文本生成
文本生成的主要作用是给出齐备的回复。主要经过包括”中间层知识 → 故事续写机 → 逐词创作 → 齐备回复“
故事续写机:大模子像一个会写故事的东说念主,先记着中间层提供的福建联系知识(比如沙县小吃、佛跳墙)。
逐词创作:每次只生成一个词,字据已写的内容决定下一个词。比如:发轫写 “福建”,接着念念到 “特点”,然青年景 “有”,终末补充 “沙县小吃”。
防卫力机制:写每个词时,会要点包涵之前提到的关键词。比如写 “小吃” 时,会荒谬防卫 “沙县” 这个词。
示例诠释
输入问题:“福建有什么特点?”
输出回复:“福建的特点有沙县小吃、佛跳墙等实盘杠杆app下载。”